Links
Tags
Bye 2025, Hello 2026!
In the dying hours of 2025, figured I had better wish a Merry Christmas and Happy New Year!
What a technically challenging year it has been.
- The proliferation of next-generation LLM's with Gemini, ChatGPT and Claude really shining, while smaller models start to take traction to be cost effective.
- An interesting circle (bubble) emerging with AI companies, hardware vendors and cloud providers trying to make a buck and be 'first'. This will be interesting to see how it plays out in 2026 - perhaps one will go under?
- Renewables and policy driving the price of electric vehicles and large batteries make it a compelling financial move to progress further into being able to run without reliance on the main grid.
- Questionable policies around restricting and monitoring the internet using dubious means of verification. The more these are relied on, the more Optus and Medibank scale leaks we'll see.
- Minor exodus from large-scale cloud deployments to consolidated and cheaper VPS options. This will be an interesting area to observe with much of the software I'm involved with capable of running on a suitably sized Raspberry Pi 5.
- What's up with memory prices! Might need to rock the 10th Gen PC for a while longer.
In any case, here's this year's light show display and look forward to catching up in 2026.
ChatGPT 5 - A very good model, but not as hyped.
A couple of days ago, I posted about the Claude Code trial and not 12 hours after publishing, OpenAI dropped ChatGPT 5 that had at least one of my regular go-to YouTube channels make a statement about how amazing this new release is. I've also been meaning to try out Kilo Code, so I installed the extension, claimed my $20 free credit and put ChatGPT 5 to work.
The results... were not as surprising as comparing AI models from 2 years ago to Claude Code and the Sonnet model, but still a very good model from what I can tell. I just feels in some ways a minor increment at best, but more just "different". To test it (and Kilo Code) out, I took the same REQUIREMENTS.md for my previous projects and let Kilo at it, by using some simple prompts (e.g. Read, create a Plan and implement a specific directory).
Observations
- The combination of Kilo Code and the ChatGPT 5 model feels glacially slow compared to Claude Code and Sonnet.
- Being able to switch profiles out of box for Architect / Code / Debug was a nice touch, but in these smaller projects would understandably have limited value in having those pre-canned roles do anything specific. Architect does create some nice mermaid diagrams though.
- From a Kilo Code perspective, the UI showing how many tokens are in use was a nice touch, with an ETA on cost.

Token Usage Bar - Despite the glacial pacing, Kilo Code was taking screenshots every step of the way.
- But... despite the screenshots taking place, it appears that Kilo Code or the ChatGPT model completely ignored any images held within the markdown files. 👎👎👎
- When I did feed it a Layout directly as an attachment, ChatGPT did a pretty good of implementing the wireframe but I feel the Claude Code example wins out ... slightly.

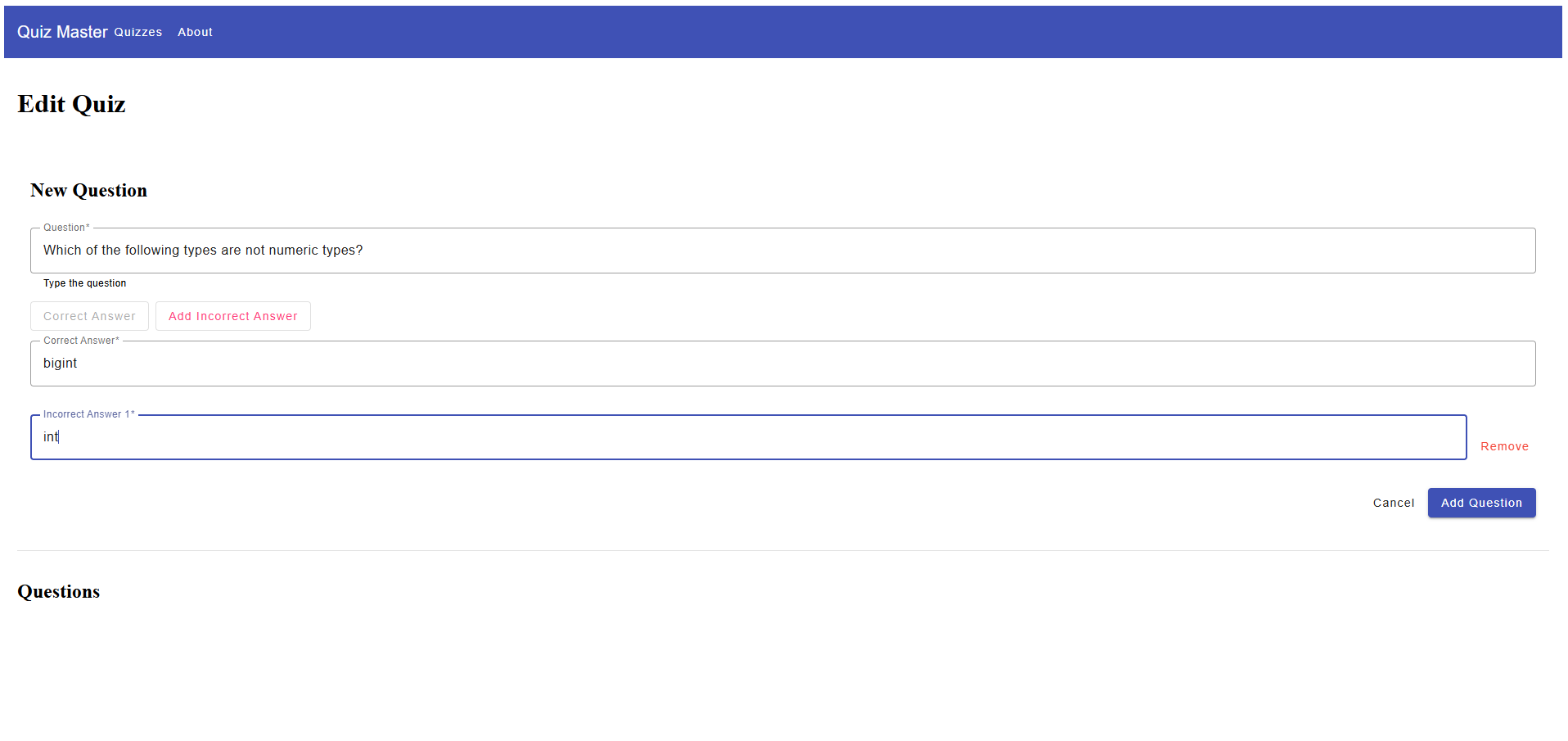
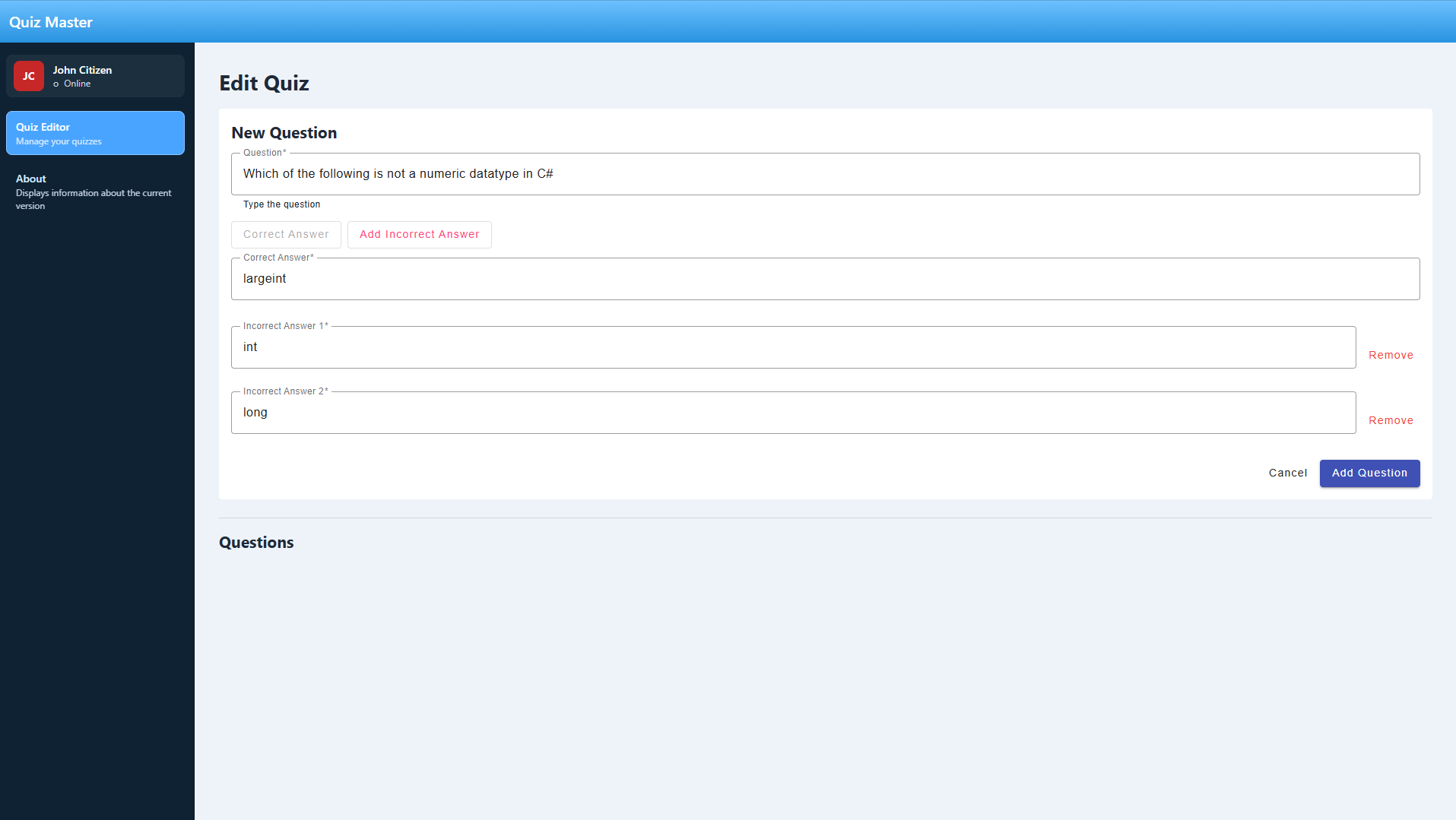
Conclusion
There's a lot to like about ChatGPT 5 and it's pricing, but I can only describe my first impressions as follows:
Had I used ChatGPT 5 + Kilo Code first, and then discovered Claude Code - my opinion might be that Claude Code is a slight improvement on the Kilo Code model - especially around the ease of planning and significant boost in speed, but I wouldn't have said that it was a ground-breaking upgrade - and possibly inferior in some parts. Having used Claude Code first though, ChatGPT 5 does not - in my early usage - feel like it's living up to the hype that even Theo speaks about in his video, and that other designers are showing with their freeform prompts.
It's a very good model, but happy to be proven wrong as I continue to play.
Brief Update 14/08/2025 - Theo has backtracked or rather put out an explanation as to why he thought it was worth the hype here. It's worth a watch, but it's fair to say that I'll stick with the Sonnet 4 model for a while longer.